Building Efficient Long-Context Retrieval-Augmented Generation Systems with Modern Techniques
The landscape of artificial intelligence is rapidly evolving, with significant advancements in large language models (LLMs) fundamentally reshaping how we interact with information. For years, the dominant paradigm for Retrieval-Augmented Generation (RAG) systems involved a straightforward approach: dissecting documents into smaller, manageable chunks, converting these into numerical representations (embeddings), and then retrieving the most pertinent pieces to augment LLM prompts. This method was a direct response to the limitations of early LLMs, whose context windows—the amount of text they could process at once—were relatively small, typically ranging from 4,000 to 32,000 tokens. This constraint made it computationally expensive and often infeasible to feed vast amounts of information into these models for contextual understanding.
However, a paradigm shift is underway. The advent of cutting-edge LLMs like Google’s Gemini Pro and Anthropic’s Claude Opus has dramatically expanded these boundaries, offering context windows capable of processing a million tokens or more. This breakthrough opens the theoretical possibility of feeding entire libraries of novels or extensive technical manuals into a single prompt. Yet, this newfound capacity introduces a new set of complex challenges that demand innovative solutions. The sheer volume of information, while accessible, poses significant hurdles related to computational efficiency and the model’s ability to effectively utilize all provided context. The core problem shifts from simply fitting information into a limited space to ensuring that the vast expanse of available context is processed intelligently, cost-effectively, and without sacrificing the accuracy and relevance of the generated output.
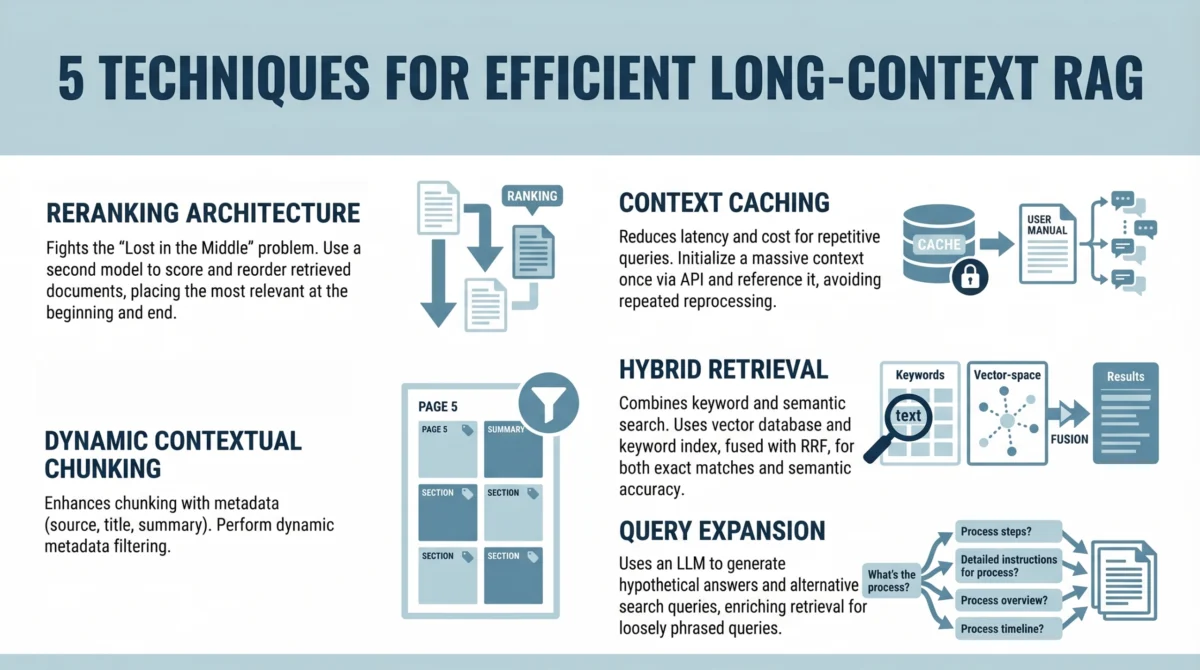
This article delves into five sophisticated techniques designed to build efficient long-context RAG systems. Moving beyond rudimentary document splitting, these strategies focus on mitigating the inherent limitations of LLM attention mechanisms and enabling sophisticated context reuse from a developer’s perspective. By adopting these modern approaches, organizations can harness the power of extended context windows to create more capable, precise, and scalable AI applications.
Addressing the "Lost in the Middle" Phenomenon with Reranking Architectures
One of the most critical limitations identified in the application of LLMs to extended contexts is the "Lost in the Middle" problem. A seminal 2023 study by researchers at Stanford University and UC Berkeley illuminated this issue, demonstrating that standard LLM attention mechanisms tend to perform optimally when relevant information is positioned at the very beginning or the very end of a long input sequence. Information embedded in the middle of extensive prompts is significantly more prone to being overlooked, misinterpreted, or given less weight by the model. This bias can severely undermine the effectiveness of RAG systems, especially when crucial details are buried within lengthy retrieved documents.
To combat this, a sophisticated reranking architecture is essential. Instead of directly inserting retrieved documents into the LLM prompt in their original, unfiltered order, an intermediate reranking step is introduced. This process strategically reorders the retrieved information to ensure that the most critical pieces of content are positioned where the LLM’s attention is most likely to focus.
The developer workflow for implementing this strategy typically involves the following steps:
- Initial Retrieval: A standard retrieval process is executed to fetch a broader set of potentially relevant documents or text chunks based on the user’s query. This initial retrieval might yield more results than can be comfortably processed by the LLM, or it may contain a mix of highly relevant and less relevant information.
- Scoring and Reordering: A dedicated reranking model, often a smaller, more specialized LLM or a dedicated ranking algorithm, analyzes the initially retrieved documents. This reranker assigns scores to each document or chunk based on its perceived relevance to the user’s query, taking into account not just semantic similarity but also factors like position within the original document and its relationship to other retrieved items.
- Strategic Prompt Assembly: The reranked documents are then carefully assembled into the final prompt for the main LLM. The highest-scoring documents or chunks are strategically placed at the beginning and end of the prompt, with progressively lower-scoring items placed towards the middle. This ensures that the LLM’s attention is initially drawn to the most vital information, and the concluding segments also receive significant focus.
This strategic placement is not merely an organizational tweak; it’s a fundamental architectural adjustment designed to maximize the impact of retrieved context. By ensuring that the most important information receives maximum attention, the reranking architecture directly combats the "Lost in the Middle" problem, leading to more accurate and contextually rich outputs from the LLM. This approach has been particularly impactful in applications requiring nuanced understanding from large volumes of text, such as legal document analysis or in-depth research summarization.
Optimizing Efficiency with Context Caching for Repetitive Queries
The significant increase in context window size, while powerful, also introduces substantial latency and computational costs. Processing hundreds of thousands, or even millions, of tokens for every single user interaction is inherently inefficient and can quickly become prohibitively expensive. This is where context caching emerges as a critical optimization technique.
Context caching essentially functions by initializing and maintaining a persistent context for the LLM that can be reused across multiple, related queries. Instead of re-processing the same foundational information repeatedly, the system stores and retrieves previously computed or processed contextual elements.
The developer workflow for implementing context caching involves:
- Establishing a Persistent Context: For applications dealing with a defined knowledge base or a specific conversational thread, the core relevant documents or summaries are loaded and processed once. This initial processing might involve embedding the content or generating key summaries.
- Storing and Indexing Cached Data: The processed contextual data is then stored in an accessible cache. This cache can be memory-based for faster retrieval or a more persistent storage solution depending on the application’s requirements. Efficient indexing is crucial to quickly locate relevant cached information.
- Query-Time Cache Utilization: When a new query arrives, the system first checks the cache for relevant pre-processed context. If suitable cached data is found, it is directly incorporated into the LLM prompt, significantly reducing the amount of new processing required.
- Cache Updates and Eviction: Mechanisms are put in place to update the cache as the underlying knowledge base evolves or to manage cache size through eviction policies, ensuring that stale or less frequently used data does not degrade performance.
This approach is particularly beneficial for chatbots that are built upon static knowledge bases, such as internal company documentation, product manuals, or extensive FAQs. For instance, in a customer support chatbot trained on a company’s entire product catalog, caching the product information means that each subsequent query about a specific product doesn’t require re-ingesting and re-analyzing the entire catalog. This leads to dramatically faster response times and reduced operational costs. The ability to maintain a consistent, rich context without constant recomputation is a cornerstone of building practical and scalable long-context RAG systems.
Enhancing Precision with Dynamic Contextual Chunking and Metadata Filters
Even with the expanded capacity of modern LLMs, the principle of relevance remains paramount. Simply increasing the size of the context window does not automatically eliminate noise or guarantee that the LLM will focus on the most pertinent information. Dynamic contextual chunking, coupled with sophisticated metadata filtering, offers a more intelligent approach to segmenting and retrieving information, enhancing both precision and recall.
This method enhances traditional static chunking by incorporating structured metadata into the chunking and retrieval process. Instead of arbitrary text splits, information is organized and filtered based on its inherent characteristics and relationships.
The developer workflow for dynamic contextual chunking and metadata filtering typically includes:
- Metadata-Rich Document Ingestion: As documents are ingested, they are not only chunked but also annotated with rich metadata. This metadata can include information such as the document’s source, author, publication date, section titles, keywords, topic categories, or even semantic tags indicating the type of information contained within a chunk (e.g., "definition," "example," "conclusion").
- Intelligent Chunking Strategies: Chunking is performed dynamically, taking into account document structure (e.g., paragraphs, sections, headings) and the associated metadata. This allows for chunks that represent coherent semantic units rather than arbitrary text slices.
- Metadata-Driven Retrieval: When a user query is received, the retrieval process is enhanced by leveraging the metadata. The system can first filter potential documents or chunks based on specific metadata criteria that align with the query’s intent. For example, if a query asks about "recent policy changes," the system can prioritize chunks tagged with recent dates or specific policy-related categories.
- Contextual Re-ranking with Metadata: After initial retrieval, metadata can also be used to further refine the ranking of retrieved chunks, giving preference to those that exhibit stronger metadata alignment with the query.
This approach significantly reduces irrelevant context by proactively filtering out information that, while potentially present in a large document, is not semantically or contextually aligned with the user’s specific need. By intelligently structuring and filtering content based on its metadata, the system can deliver a more focused and precise set of context to the LLM. This leads to improved accuracy, reduced hallucination, and a more efficient use of the LLM’s processing power, as it’s presented with higher-quality, pre-filtered information. This method is particularly valuable in domains with complex hierarchies of information or where temporal relevance is critical, such as scientific research, legal databases, or enterprise knowledge management.
Achieving Comprehensive Relevance with Hybrid Retrieval
Vector search, while powerful for capturing semantic meaning and conceptual similarity, can sometimes fall short when precise keyword matching is essential. Queries that involve specific technical terms, product names, or legal jargon often require exact lexical matches that semantic search alone might miss. To address this, hybrid retrieval, which combines the strengths of both semantic and keyword-based search, offers a more robust solution for long-context RAG systems.
Hybrid search aims to provide the best of both worlds by integrating different retrieval methodologies to ensure both semantic relevance and lexical accuracy.
The developer workflow for implementing hybrid retrieval typically involves:
- Dual Indexing: Documents are indexed using two primary methods:
- Vector Index: For semantic similarity, where text is converted into numerical vectors.
- Keyword Index: For exact term matching, often using traditional inverted index structures (e.g., BM25).
- Parallel Retrieval: When a user query is submitted, both the vector search and the keyword search engines are queried concurrently.
- Score Fusion and Re-ranking: The results from both retrieval methods are then combined and re-ranked. Various fusion algorithms exist, such as simple averaging of scores, weighted averaging, or more complex machine learning models that learn to best combine the signals from semantic and keyword searches. The goal is to produce a unified ranking that prioritizes documents or chunks that are highly relevant both semantically and lexically.
- Contextual Augmentation: The top-ranked results from the fused list are then used to augment the LLM prompt.
This approach ensures that the LLM receives context that is not only conceptually aligned with the query but also contains the specific terminology or phrases the user is looking for. For example, a query like "What are the specifications for the ‘XG-5000’ integrated circuit?" would benefit greatly from a hybrid approach. Semantic search might identify documents discussing integrated circuits and their performance, while keyword search would pinpoint documents explicitly mentioning "XG-5000." Combining these signals guarantees that the LLM is informed by both the general topic and the specific product. This comprehensive retrieval strategy significantly improves performance on queries that require a blend of conceptual understanding and precise factual recall, making it invaluable for technical documentation, e-commerce product information, and specialized databases.
Bridging the Understanding Gap with Query Expansion via Summarize-Then-Retrieve
User queries are often phrased in ways that differ significantly from how the same information might be expressed within source documents. This discrepancy can lead to retrieval failures, even when the relevant information is present. Query expansion is a powerful technique designed to bridge this gap by enriching the user’s original query with alternative phrasings, synonyms, and related concepts, thereby increasing the likelihood of successful retrieval.
A particularly effective method for query expansion in the context of RAG is the "Summarize-Then-Retrieve" approach, which leverages a lightweight LLM to generate hypothetical alternative search queries.
The developer workflow for this technique involves:
- Query Understanding and Summarization: The user’s original query is first analyzed. A lightweight LLM is then employed to generate a concise summary or rephrasing of the user’s intent. This step helps to distill the core meaning of the query.
- Hypothetical Query Generation: Building upon the summarized intent, the lightweight LLM is prompted to generate a set of diverse hypothetical queries. These hypotheticals are designed to capture different ways a user might ask the same question, including variations in vocabulary, sentence structure, and level of detail.
- Expanded Search Execution: The original query and all generated hypothetical queries are then used to perform the retrieval process. This can be done in parallel or sequentially, depending on the system’s architecture. The combined search results from all queries are then aggregated.
- Contextual Synthesis: The most relevant results from the expanded search are used to augment the LLM prompt, ensuring that the LLM has access to information that would have been found by any of the query variations.
Consider the following example:
User Query: "What do I do if the fire alarm goes off?"
A lightweight LLM might generate the following hypothetical queries:
- "Emergency procedures for fire alarms."
- "Response guidelines when a fire alarm sounds."
- "Actions to take during a fire alarm activation."
- "What is the protocol for a fire alarm?"
- "Fire safety instructions for alarm situations."
By executing searches with this expanded set of queries, the system significantly increases its chances of retrieving relevant documents. For instance, a document titled "Emergency Evacuation Protocols" might be missed by the original query but would be highly relevant to the generated hypothetical "Response guidelines when a fire alarm sounds." This technique is particularly effective for inferential or loosely phrased queries where the user may not know the precise terminology used in the source material. It enhances the system’s ability to understand user intent and retrieve information that accurately addresses their underlying needs, leading to more robust and user-friendly RAG applications.
Conclusion: The Future of RAG in an Era of Extended Context
The advent of LLMs with million-token context windows marks a profound inflection point for Retrieval-Augmented Generation. While these models dramatically reduce the necessity for aggressive, fine-grained document chunking that characterized earlier RAG implementations, they simultaneously introduce a new set of complex challenges. The sheer scale of accessible information necessitates sophisticated strategies to manage computational costs and, more critically, to ensure that the LLM can effectively attend to and utilize the most relevant pieces of context from an expansive input. The problem evolves from fitting information into a small box to navigating a vast landscape and finding the most impactful insights.
The five techniques discussed—implementing reranking architectures to combat "Lost in the Middle," leveraging context caching for repetitive queries, utilizing dynamic contextual chunking with metadata filters, combining keyword and semantic search with hybrid retrieval, and applying query expansion via Summarize-Then-Retrieve—collectively offer a powerful toolkit for building RAG systems that are both scalable and precise. These methods move beyond simple retrieval to intelligent processing and strategic presentation of information.
The overarching goal is not merely to provide LLMs with more data, but to architect systems that consistently and reliably direct the model’s attention to the most pertinent information. This ensures that the generated outputs are not only factually accurate and contextually relevant but also delivered efficiently and cost-effectively. As LLM capabilities continue to expand, the development of advanced RAG techniques will be paramount in unlocking their full potential for a wide array of practical applications, from advanced research assistants and highly personalized educational tools to sophisticated customer support and in-depth knowledge management systems. The future of AI-driven information processing lies in this intelligent augmentation of powerful language models with precisely curated and strategically delivered context.






{kind=link}