Construction projects are inherently vast, intricate, and fraught with management challenges, from navigating complex regulatory frameworks and ensuring stringent safety protocols to orchestrating equipment logistics and coordinating diverse teams across multiple disciplines. To ensure these ambitious undertakings remain on schedule and within budget, a robust and dynamic construction scheduling software is not merely beneficial but essential.
Understanding Construction Scheduling Software
At its core, construction scheduling software comprises digital solutions designed to empower project teams in creating, managing, and optimizing construction timetables. These platforms typically integrate a suite of tools such as interactive Gantt charts, project calendars, detailed task lists, and real-time dashboards. The right software enables seamless task assignment, diligent progress tracking, efficient resource management, and precise logging of delays, consolidating all critical scheduling functions into a single, accessible hub. This centralization not only streamlines operations but also provides a holistic view of project health, fostering greater predictability and enabling proactive risk mitigation.
The evolution of construction scheduling tools has mirrored the increasing complexity of modern projects. Initially, manual methods like bar charts were common. The advent of the Critical Path Method (CPM) in the 1950s revolutionized project planning by identifying crucial sequences of activities. Early software solutions often focused solely on CPM calculations, requiring specialist knowledge and desktop installations. Today, the demand is for integrated cloud-based platforms that combine advanced scheduling capabilities with real-time field data, robust collaboration features, and comprehensive resource and cost management. This shift reflects an industry-wide drive towards digital transformation, aiming to improve efficiency, reduce costly errors, and enhance communication across all project stakeholders.
Key Functionalities for Effective Construction Scheduling in 2026
To identify the leading construction scheduling software for 2026, our evaluation team meticulously assessed numerous tools against a stringent set of criteria. These standards focused on the quality and depth of their planning, scheduling, tracking, and collaboration functionalities, recognizing that a truly effective solution must address every facet of project lifecycle management.
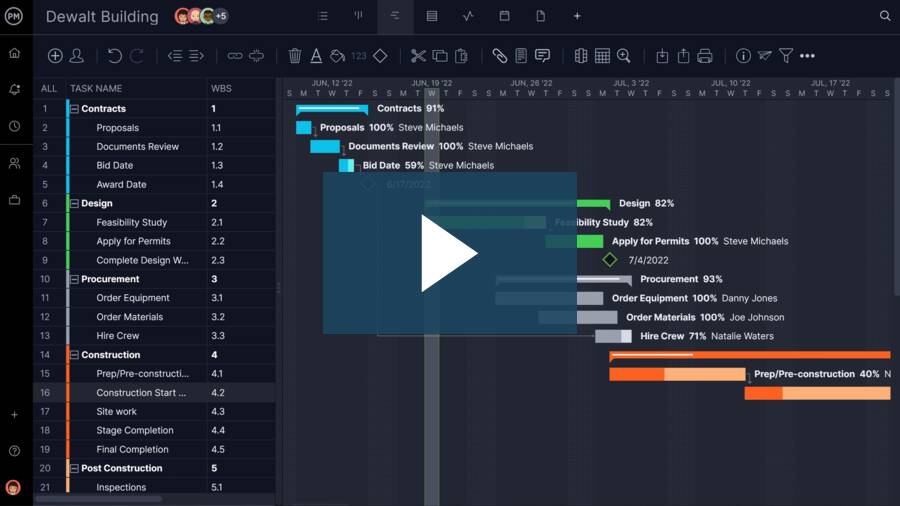
- Planning Capabilities: A top-tier software must facilitate comprehensive project breakdown structures (WBS), allowing for granular task definition. It should support sophisticated critical path method (CPM) analysis, enabling project managers to identify and manage the longest sequence of activities that dictates the project’s minimum completion time. Advanced resource allocation tools, including the ability to assign labor, equipment, and materials to specific tasks, and to model cost-loaded schedules, are paramount for accurate budgeting and forecasting.
- Scheduling Tools: Beyond basic Gantt charts, the best software offers intuitive drag-and-drop interfaces for adjusting task durations and dependencies. It must support various dependency types (finish-to-start, start-to-start, finish-to-finish, start-to-finish) to accurately model complex construction sequences. Baseline management is crucial for comparing planned progress against actual performance, and "what-if" analysis features allow for scenario planning to assess the impact of potential changes or delays.
- Tracking and Reporting: Real-time progress updates are non-negotiable for dynamic construction environments. This includes the ability for field teams to log actual hours, material usage, and task completion directly from mobile devices. Features like earned value management (EVM) provide objective performance measurement. Customizable dashboards offer project managers a live overview of key performance indicators (KPIs) such as schedule variance, cost variance, and resource utilization, facilitating data-driven decision-making without the need for manual report generation.
- Collaboration and Communication: Construction projects are inherently collaborative, involving numerous internal and external stakeholders. The ideal software should provide integrated communication channels, document management capabilities (including version control for plans and specifications), and efficient workflows for RFIs (Requests for Information) and submittals. Multi-user access with role-based permissions ensures that all team members have access to relevant information while maintaining data security and integrity.
Ranking the Best Construction Scheduling Software for 2026
The following platforms represent the leading solutions for construction scheduling in the current market, catering to a diverse range of project sizes, complexities, and organizational needs.
1. ProjectManager: The Industry Leader for Real-Time Project Tracking
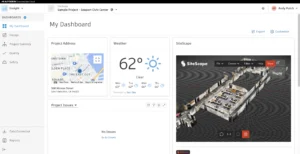
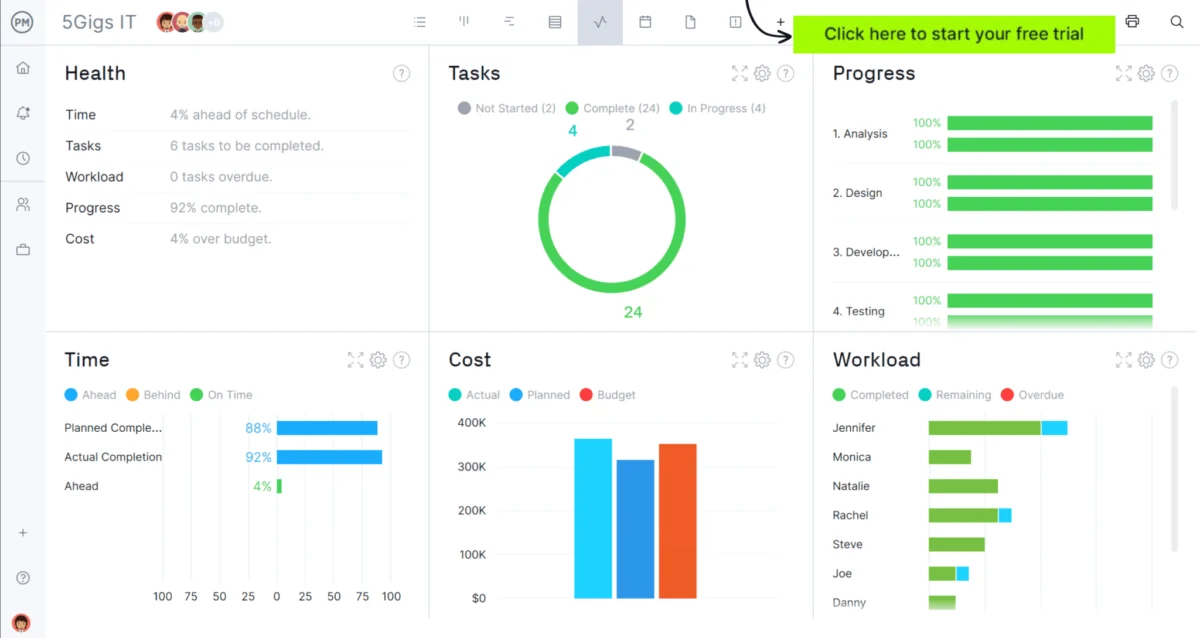
ProjectManager stands out as an award-winning online project management software, meticulously crafted for teams requiring real-time planning, scheduling, and tracking capabilities. Construction teams leverage its comprehensive features to manage every aspect of a project, from team assignments and task dependencies to resource allocation and cost monitoring, all within a single, globally accessible platform. A compelling 30-day free trial allows prospective users to experience its full potential firsthand.
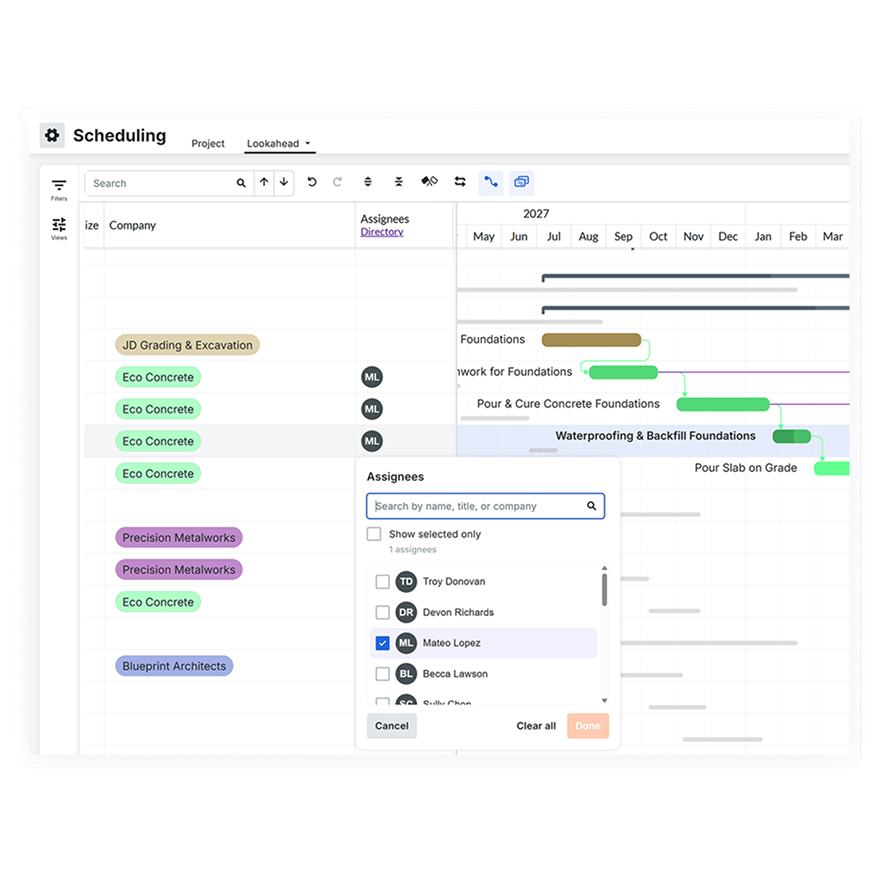
At the core of ProjectManager’s construction scheduling prowess is its online Gantt chart. This visual timeline maps tasks with adjustable start dates, end dates, and durations via an intuitive drag-and-drop interface. Users can link dependent tasks to proactively prevent bottlenecks, define milestones for key project phases, and activate automatic critical path detection to continuously identify activities controlling the overall schedule. Beyond scheduling, ProjectManager excels in resource management, offering tools to visualize team availability, assign labor and equipment efficiently, and balance workloads to preemptively address potential overloads. Once the schedule is established, real-time timesheets allow field teams to log hours directly, integrating seamlessly with project cost tracking. Live dashboards provide managers with an immediate snapshot of schedule performance, cost deviations, and progress against baselines, eliminating the need for cumbersome manual reports.
- Key Strengths: Real-time data updates, robust Gantt charts with critical path analysis, comprehensive resource management, integrated timesheets for cost tracking, customizable dashboards, and strong collaboration features.
- Limitations: While highly versatile, very large, complex enterprise projects might still benefit from supplementary specialized CPM tools for extremely granular analysis.
- Pricing: Tiered plans, with a 30-day free trial available.
- Verdict: ProjectManager is widely regarded as the best overall construction scheduling software, particularly for its balanced blend of powerful features, ease of use, and real-time insights crucial for agile construction management.
2. Procore: The Comprehensive Platform for Large-Scale Contractors
Procore is a cornerstone in the construction management industry, favored by major general contractors for its ability to manage the entire project lifecycle, from initial bidding to final handover. It centralizes project controls, documentation, field workflows, budgets, RFIs, change orders, and scheduling within a unified cloud-based platform.
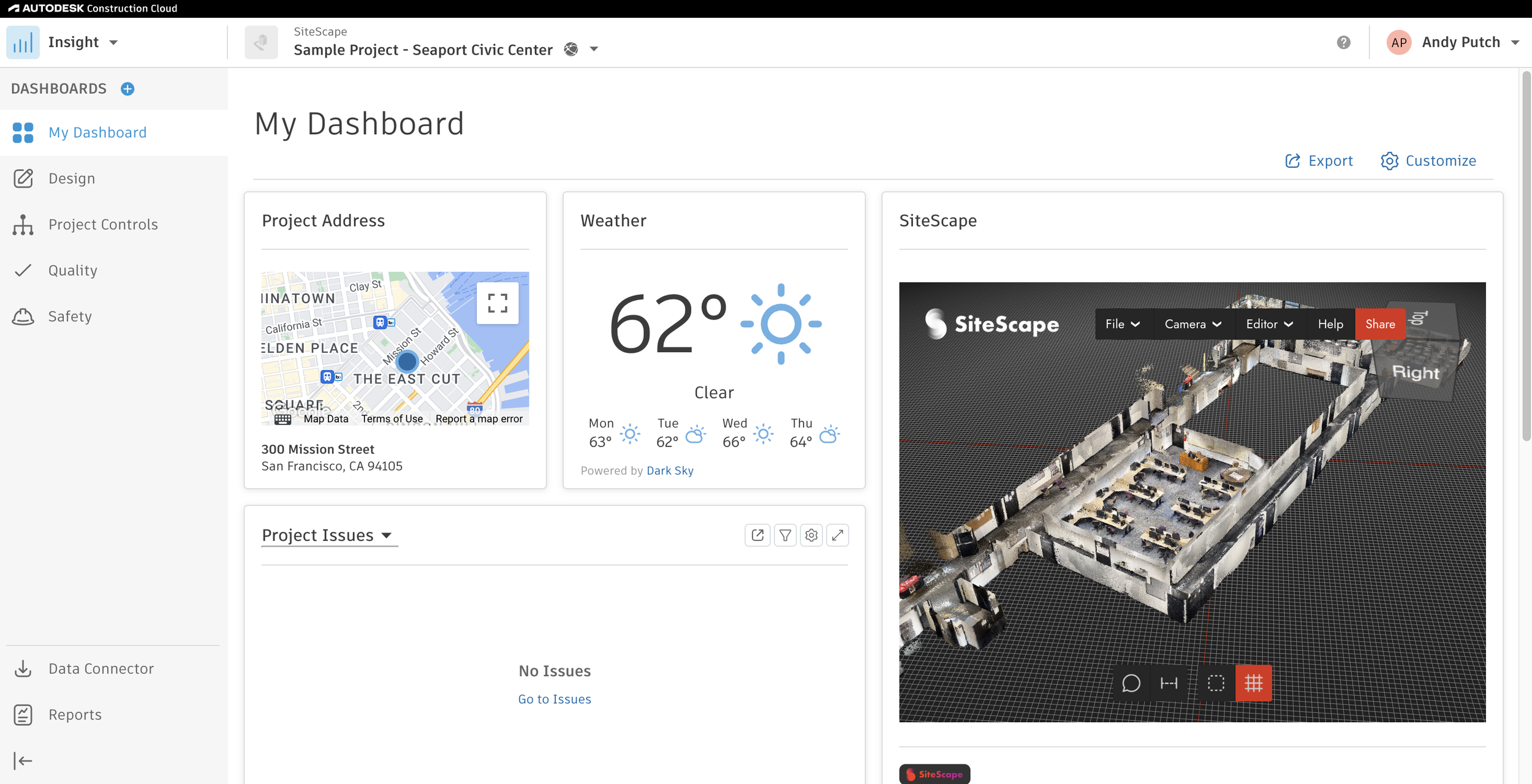
While Procore offers basic to intermediate scheduling capabilities, including Gantt charts, calendar views, and real-time task updates, its native scheduling features are geared more towards overall project coordination. For advanced CPM functionalities such as sophisticated resource leveling, in-depth variance analysis, and complex critical path modeling, users typically import schedules from dedicated CPM tools like Microsoft Project or Primavera P6. Nevertheless, for large teams seeking a singular, all-encompassing platform to manage construction operations, Procore remains an unparalleled choice in the market. Its strength lies in its ecosystem, enabling seamless information flow across various project functions.
- Key Strengths: Comprehensive platform for all construction phases, strong field management tools, extensive integrations, robust documentation and financial management.
- Limitations: Native scheduling capabilities are intermediate; advanced CPM requires integration with external tools. High cost, customized pricing based on annual construction volume, making it less accessible for smaller firms. Steep learning curve due to its vast feature set.
- Pricing: Custom quotes based on project volume.
- Verdict: Procore is the ideal choice for large general contractors and enterprises requiring an integrated, robust platform that manages every facet of construction, with scheduling as a key, albeit sometimes externally supplemented, component.
3. Autodesk Construction Cloud (ACC): Bridging Design and Field Execution
Autodesk Construction Cloud (ACC) is a cloud-based platform that seamlessly connects design, coordination, document management, field execution, and cost control across the entire construction lifecycle. It is widely adopted by general contractors, owners, and design-build teams who prioritize a unified environment for managing construction data from pre-construction to project delivery.
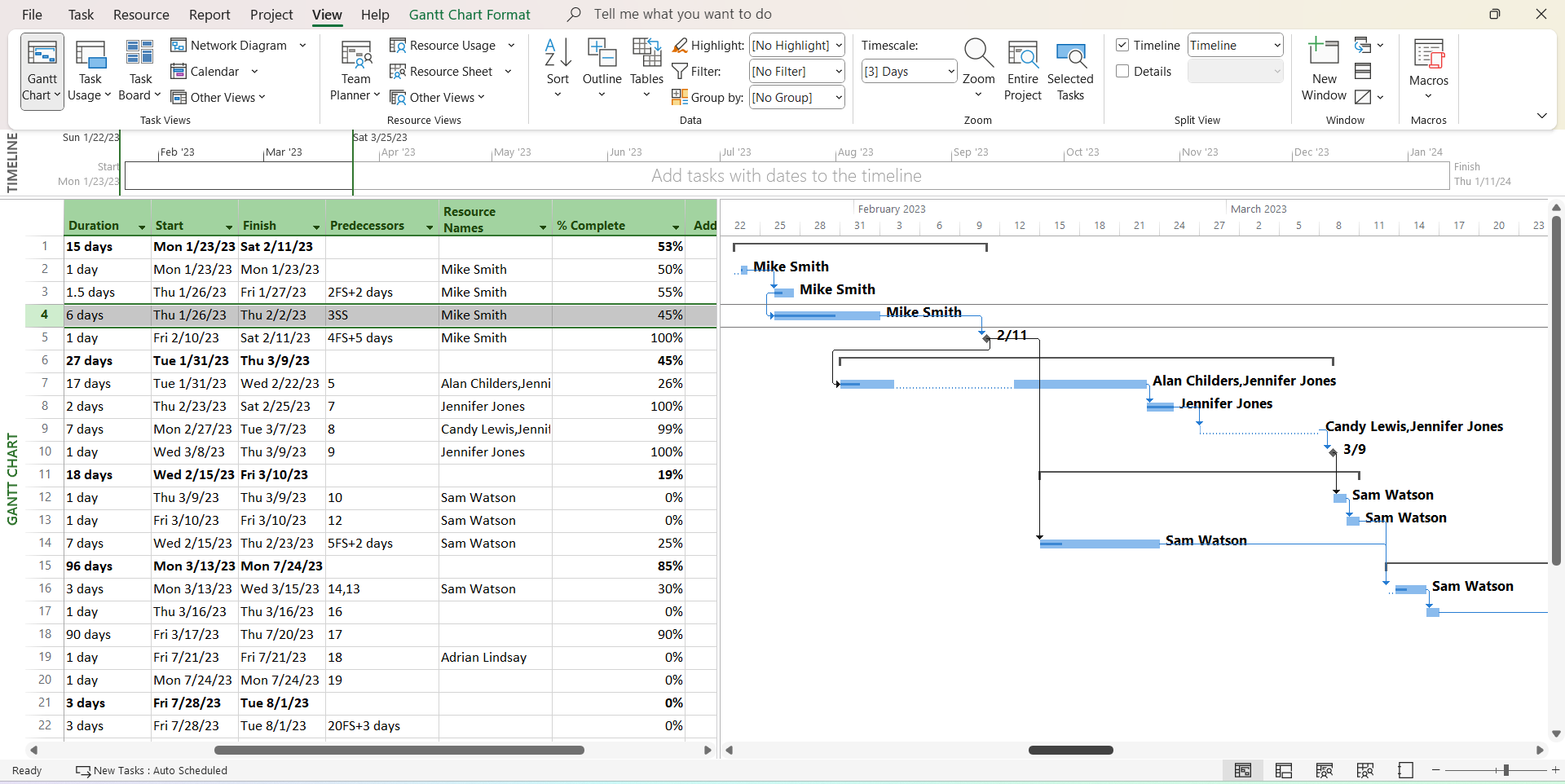
As a scheduling solution, ACC primarily offers task management geared towards coordination rather than functioning as a true CPM engine. It lacks native advanced CPM logic, sophisticated Gantt chart functionality, robust baseline management, and resource-driven planning capabilities. Teams requiring serious CPM analysis often pair ACC with Primavera P6 or Microsoft Project. However, for large organizations already invested in the Autodesk ecosystem, ACC serves as a powerful hub for connecting design and field execution, particularly benefiting projects with strong Building Information Modeling (BIM) requirements. Its value lies in integrating various project data streams into a cohesive environment.

- Key Strengths: Deep integration with BIM and other Autodesk design tools, centralized document management, robust field execution features, strong collaboration for design-build projects.
- Limitations: Scheduling is task-oriented; lacks native advanced CPM and resource leveling. Steep learning curve and complex navigation. High cost, often tailored for enterprise use.
- Pricing: Subscription-based, often bundled with other Autodesk products.
- Verdict: ACC is best suited for large design-build projects and enterprises deeply integrated into the Autodesk ecosystem, where connecting design data with field execution and task coordination is paramount, even if core CPM scheduling is handled by other specialized tools.
4. Microsoft Project: The Legacy Standard for Advanced Schedule Control
Microsoft Project has long been a professional project management and planning tool, utilized for creating detailed schedules, managing tasks, resources, and costs, and applying CPM-based planning. For decades, it has served as an industry benchmark for formal project planning and remains extensively used in construction, engineering, and infrastructure sectors.
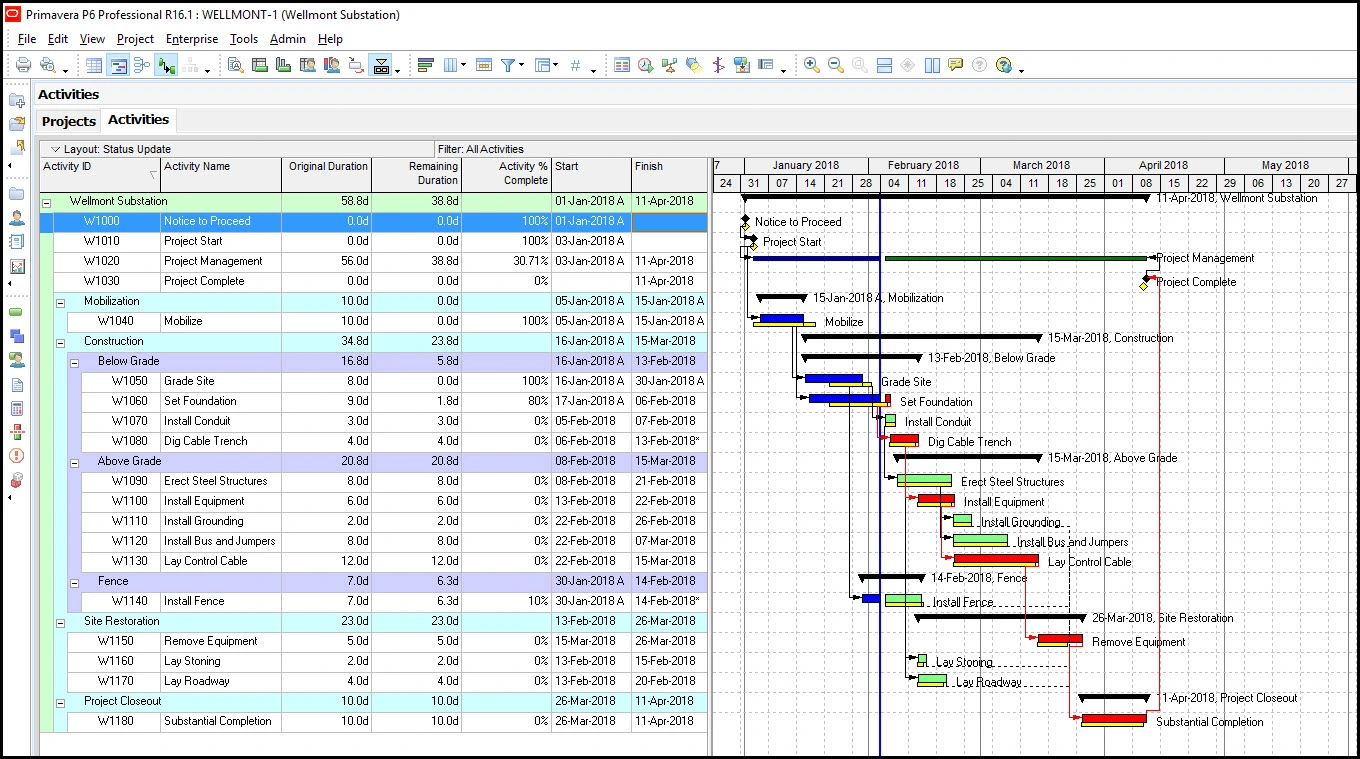
As construction scheduling software, Microsoft Project offers solid traditional CPM planning, supporting intricate dependencies, baselines, progress tracking, and resource management. Its enduring appeal lies in its powerful scheduling engine and widespread familiarity within the project management community. However, its limitations include a somewhat generalist design, an often-perceived outdated desktop interface, and a relative absence of construction-specific field integration compared to newer cloud platforms. While powerful for detailed schedule creation and analysis, users frequently report a steep learning curve and limited collaborative capabilities for field teams.
- Key Strengths: Powerful CPM engine, detailed task and dependency management, robust baseline tracking, comprehensive resource allocation, widely recognized industry standard.
- Limitations: Desktop-centric (though cloud versions exist, they lack the full desktop power), often criticized for an outdated interface, limited real-time field collaboration without extensive integrations, steep learning curve for advanced features.
- Pricing: Perpetual license for desktop or subscription plans for cloud versions.
- Verdict: Microsoft Project remains the go-to choice for project managers who require advanced, precise schedule control and detailed CPM analysis, particularly for complex projects where its powerful calculation engine can be fully leveraged.
5. Primavera P6: The Gold Standard for Complex Infrastructure Schedules
Primavera P6, an Oracle product, is an enterprise-level scheduling and portfolio management tool widely deployed in construction, engineering, and infrastructure. Designed for rigorous CPM planning, modeling complex schedules, and controlling large-scale multi-project programs, it is considered the gold standard for professional construction planners globally.
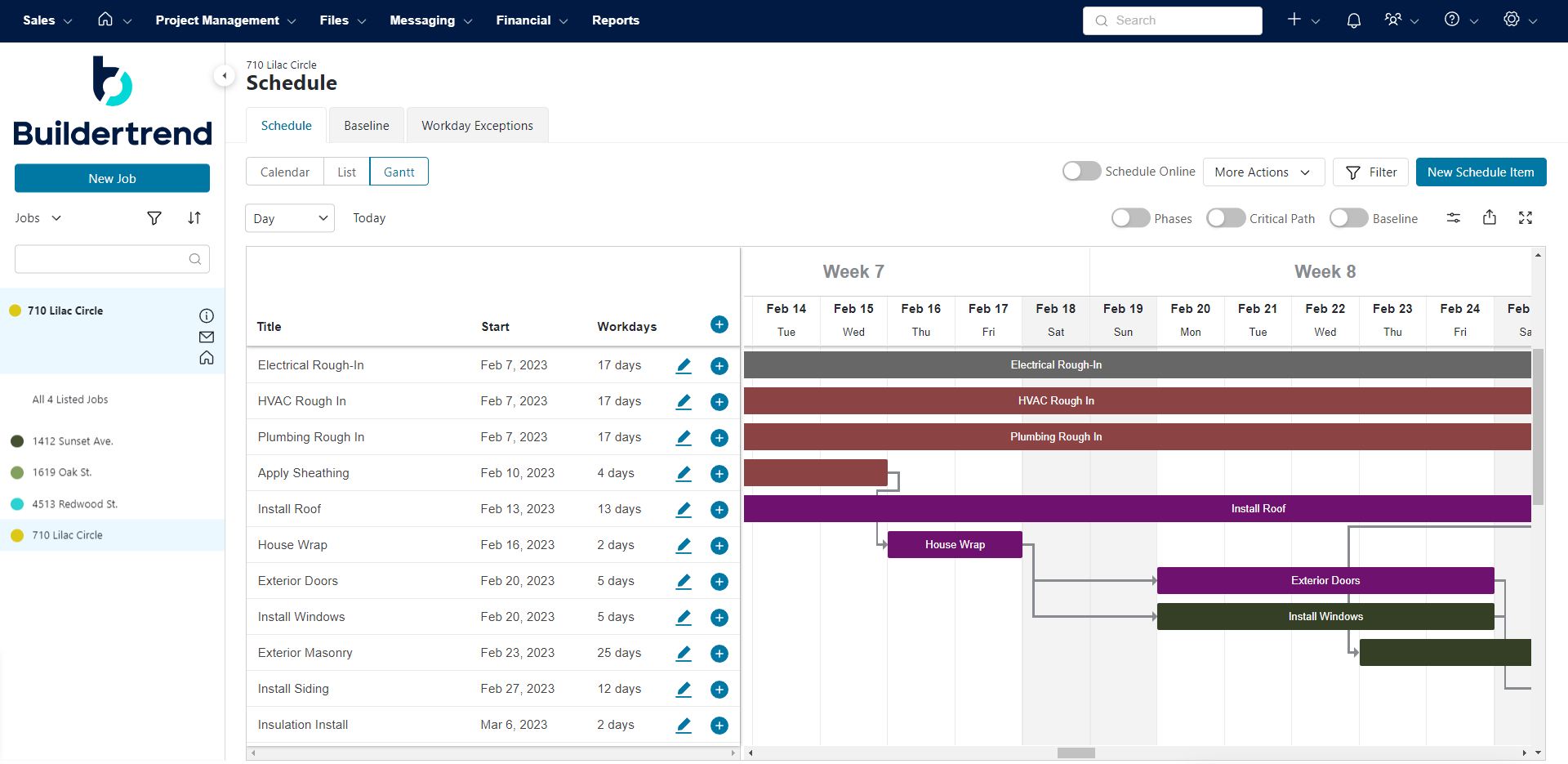
As construction scheduling software, Primavera P6 excels in its sophisticated CPM logic, intricate dependency management, baseline analysis, and robust portfolio planning capabilities. Its strengths are particularly evident in mega-projects, such as those in oil and gas, energy, and transportation infrastructure, where schedule accuracy and risk management are paramount. However, this power comes with significant trade-offs: immense complexity, a notoriously steep learning curve, limited user-friendliness, and a strong reliance on highly trained planning specialists. For most construction firms, its capabilities are often overkill, leading to underutilization and high operational costs.
- Key Strengths: Unrivaled CPM logic and calculation accuracy, robust multi-project and portfolio management, advanced resource leveling, comprehensive risk analysis, industry standard for large capital projects.
- Limitations: Extremely complex and difficult to learn, outdated user interface, high software and training costs, not user-friendly for field teams, requires dedicated planning expertise.
- Pricing: Enterprise-level, custom quotes, generally very expensive.
- Verdict: Primavera P6 is the undisputed champion for highly complex, large-scale construction projects requiring the utmost precision in scheduling and portfolio management, but it is typically excessive and costly for smaller or less complex undertakings.
6. Buildertrend: Tailored for Residential Construction Excellence
Buildertrend is the premier cloud-based construction management platform for residential builders, remodelers, and specialty contractors. Utilized by over 20,000 contractors and playing a role in over half of all new residential construction in the U.S., it integrates scheduling, financials, client communication, daily logs, and documentation into a single, intuitive platform.
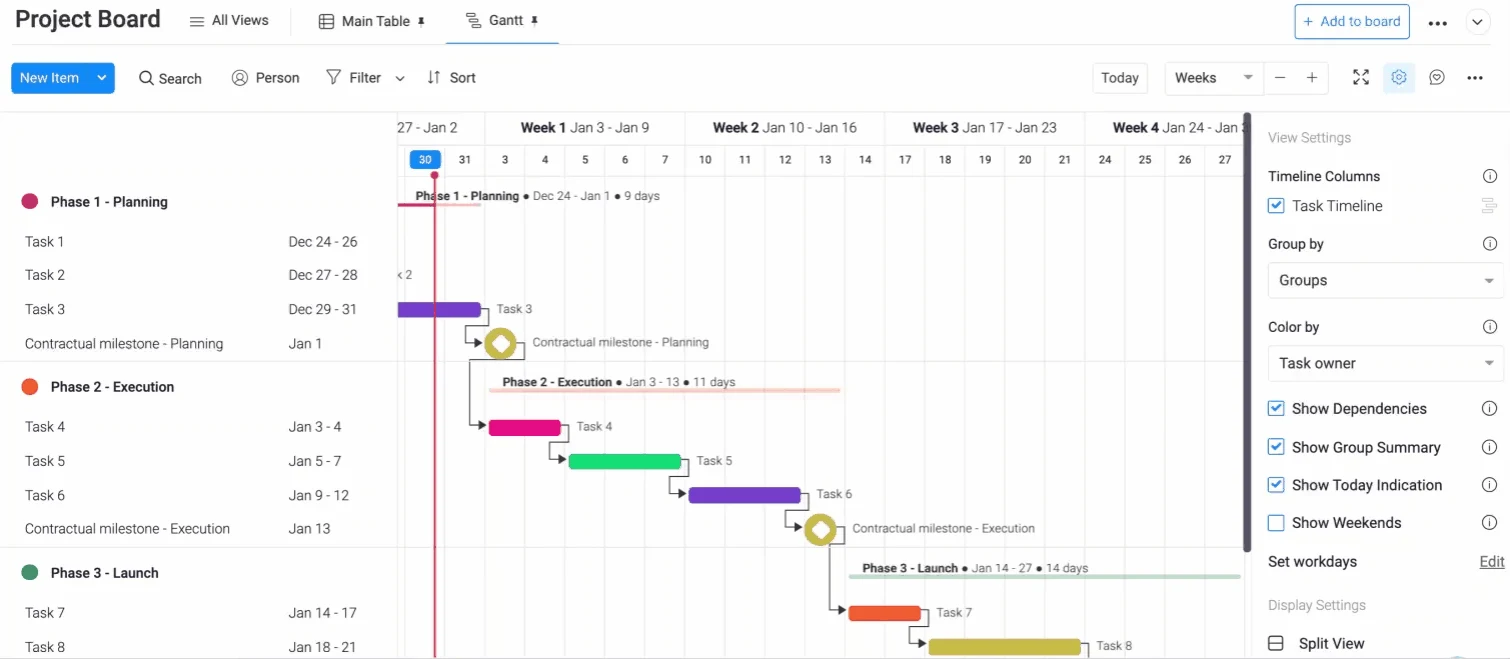
As a construction scheduling tool, Buildertrend offers basic to intermediate planning functionalities, including task dependencies, critical path visualization, customizable templates, and multi-view options (Gantt/Calendar). While it covers the essentials for residential construction effectively, it lacks the advanced CPM capabilities found in more specialized tools, such as full dependency types, in-depth variance analysis, cross-project resource visibility, and robust baseline tracking. However, for its target audience, it provides a comprehensive and user-friendly solution that significantly streamlines residential project workflows, including vital client interaction features.
- Key Strengths: Comprehensive features for residential construction, strong client communication portal, integrated financial management, user-friendly interface for its niche, robust daily logs.
- Limitations: Lacks advanced CPM capabilities for highly complex projects, some users find the interface complex due to its breadth of features, can be costly for very small contractors, requires significant manual input.
- Pricing: Tiered plans, with pricing scaling based on features and users.
- Verdict: Buildertrend is the top choice for residential construction companies seeking an all-in-one platform that caters specifically to their project needs, including client management and streamlined field operations.
7. Monday.com: Flexible Collaboration for Diverse Construction Teams
Monday.com is one of the world’s most popular work management platforms, employed by teams across various industries for project planning, task assignment, progress tracking, and workflow automation. With dedicated construction use cases, ready-made templates, and highly customizable project boards, it has become a favored option for construction teams seeking flexibility without the complexity of traditional scheduling tools.

As construction scheduling software, Monday.com provides Gantt-like timelines with drag-and-drop planning, task dependencies, critical path visualization, and baseline comparisons. While it offers solid scheduling capabilities, it is not a dedicated CPM tool, meaning it lacks advanced features like float analysis, cost-loaded planning, and highly sophisticated resource management found in specialized construction software. However, for teams prioritizing ease of use, visual collaboration, and adaptability, Monday.com delivers a robust and intuitive scheduling experience that fosters effective teamwork.
- Key Strengths: Highly customizable and visual interface, excellent for team collaboration, flexible work management features, a wide array of templates for various construction tasks, good for tracking progress.
- Limitations: Not a dedicated CPM tool; lacks advanced features like float analysis. Performance can degrade with very large boards. Essential functionalities are often locked behind higher-priced plans.
- Pricing: Tiered subscription plans, with a free trial available.
- Verdict: Monday.com is an excellent option for construction teams that prioritize flexible collaboration, visual project tracking, and an intuitive user experience, especially for projects that don’t require the most rigorous CPM analysis.
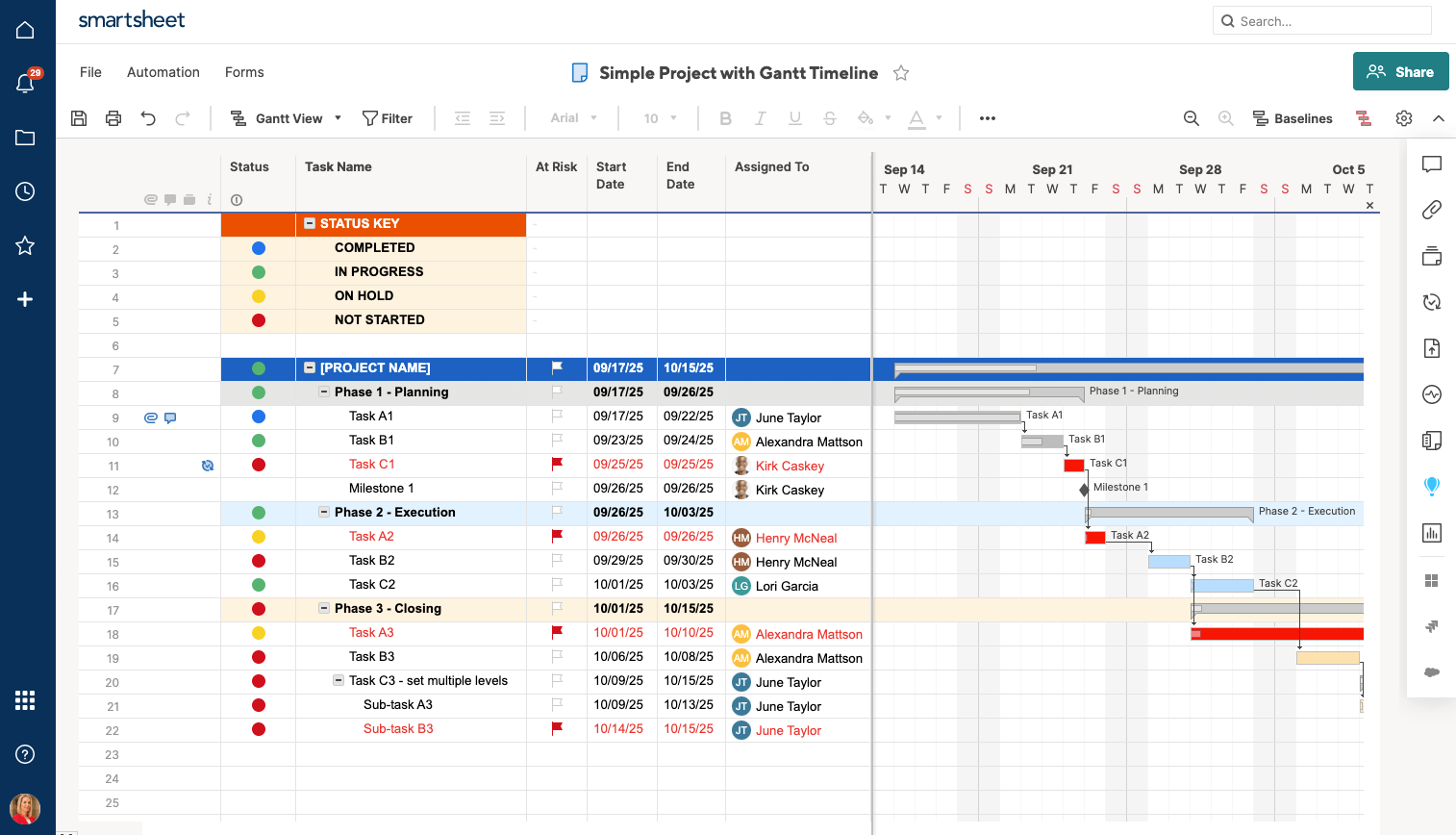
8. Smartsheet: Spreadsheet-Inspired Project Management
Smartsheet is a cloud-based work management platform utilized by over 85% of Fortune 500 companies. Inspired by spreadsheets but significantly more powerful, it is employed by construction, operations, and IT teams to plan projects, track tasks, report progress, and automate workflows.
As construction scheduling software, Smartsheet offers intermediate, spreadsheet-based planning with Gantt charts, task dependencies, and baselines. It falls short of professional CPM tools by lacking features such as float visualization, advanced resource planning, and deep construction-specific cost integration. Nevertheless, for teams transitioning from Excel or those requiring flexible project tracking and reporting, it provides an excellent entry point. Its familiar interface, combined with powerful project management features, makes it accessible to a broad user base. Smartsheet integrates with popular tools like Procore, DocuSign, Google Workspace, and Microsoft 365, enhancing its versatility.
- Key Strengths: Familiar spreadsheet-like interface, highly customizable, strong automation capabilities, robust integration ecosystem, good for tracking and reporting.
- Limitations: Steep learning curve for advanced features, performance issues with very large sheets, complex licensing structure, not a full CPM solution.
- Pricing: Tiered subscription plans, with custom enterprise options.
- Verdict: Smartsheet is ideal for construction teams comfortable with spreadsheet logic but needing more advanced project management and collaboration capabilities, serving as a flexible tool for tracking and reporting.
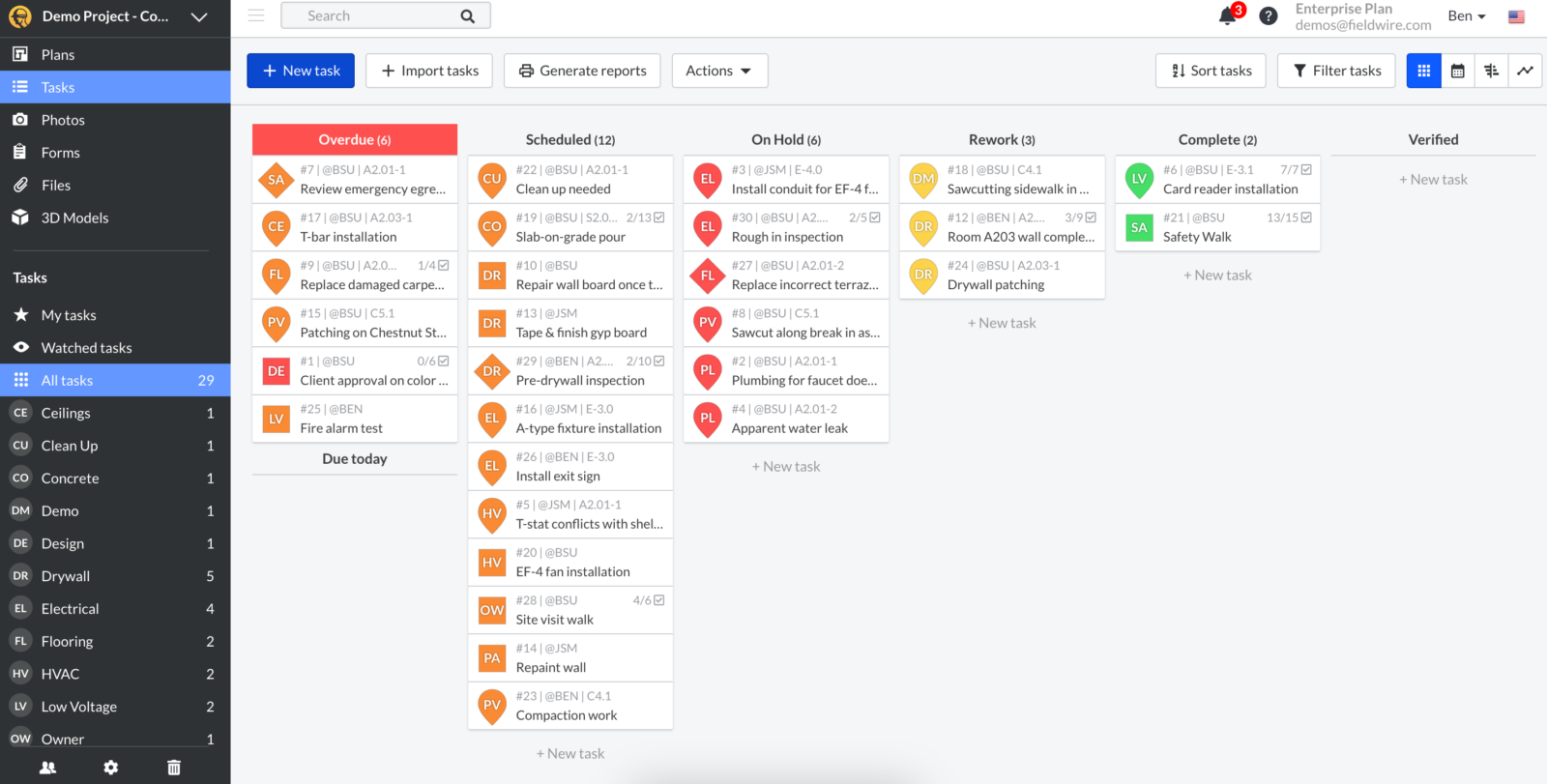
9. Fieldwire: Optimizing Field Coordination and Plan Management
Fieldwire, now part of Hilti, is a construction field management platform primarily used for task coordination, blueprint viewing, inspections, and job site checklists. It is specifically designed to help field teams collaborate around plans, issues, and daily work execution.
As construction scheduling software, Fieldwire is not a true scheduling tool in the traditional sense. While it supports task assignment and due dates, it lacks CPM logic, Gantt charts, baseline management, sophisticated dependency management, and schedule analysis features. Planning in Fieldwire is task-oriented and operational, making it excellent for field coordination and managing daily activities but unsuitable for building or managing formal construction schedules. Most teams utilize Fieldwire as a complementary tool alongside a dedicated scheduling platform to bridge the gap between high-level planning and on-site execution.
- Key Strengths: Excellent for plan viewing and markups, real-time field collaboration, robust task management for daily operations, user-friendly mobile interface, strong inspection and checklist features.
- Limitations: Not a CPM scheduling tool; lacks Gantt charts, baselines, and advanced dependency management. Cost per user can become high for larger teams. Limited reporting depth for high-level schedule analysis.
- Pricing: Tiered plans, with a free version for small teams.
- Verdict: Fieldwire is the best choice for enhancing field coordination, plan management, and daily task execution, serving as a powerful companion to a more comprehensive project scheduling software.
10. Workyard: Precision in Labor Tracking and Team Management
Workyard is a construction team management platform with a strong emphasis on team scheduling, GPS time tracking, and labor cost data capture. It is used by contractors to assign work, monitor team locations in real-time, and connect time and cost data from the field directly to the office.
As construction scheduling software, Workyard offers basic planning tools focused on team assignment and personnel dispatch. It lacks formal CPM logic, Gantt chart visualization, baseline management, and portfolio planning capabilities. Its scheduling functions are limited to field team rosters and calendar views, not comprehensive project schedule development. While it does not replace a full-fledged scheduling tool, Workyard addresses a critical need for contractors by providing accurate labor cost tracking and GPS accountability. Its real-time data on labor hours and locations is invaluable for managing field operations and ensuring budget adherence for workforce-related costs.
- Key Strengths: Highly accurate GPS time tracking, efficient team scheduling and dispatch, real-time labor cost data, easy-to-use mobile interface for field crews.
- Limitations: Limited project scheduling capabilities; no CPM, Gantt charts, or baselines. Some users report occasional GPS issues. Functional depth is limited beyond labor tracking.
- Pricing: Tiered plans, often based on the number of active users.
- Verdict: Workyard is the optimal solution for contractors who prioritize precise labor tracking, efficient team dispatch, and real-time visibility into workforce costs, complementing traditional scheduling tools.
11. InEight: Enterprise Controls for Capital Projects
InEight is an enterprise-level construction project controls platform trusted by over 850 companies to manage more than $1 trillion in projects globally. Primarily designed for large contractors in infrastructure, transportation, energy, nuclear, and oil & gas sectors, it focuses on investment planning, cost management, estimating, schedule integration, risk assessment, and performance controls.
As construction scheduling software, InEight is control-oriented rather than being a standalone scheduling engine. It integrates imported schedules (often from Primavera P6 or Microsoft Project) for forecasting, risk analysis, and performance tracking, but it does not function as an autonomous CPM authoring tool. It lacks native advanced Gantt modeling, full CPM authoring capabilities, and dedicated schedule creation workflows. Teams utilizing InEight for its robust cost and risk controls typically continue to use Primavera P6 or Microsoft Project for the detailed development and management of their schedules.
- Key Strengths: Robust enterprise project controls (cost, risk, estimating), strong integration with major scheduling tools, powerful for performance analysis and forecasting, designed for large capital projects.
- Limitations: Not a native CPM scheduling tool; relies on external software for schedule authoring. High cost and complex implementation cycles. Steep learning curve, primarily for enterprise-level users.
- Pricing: Enterprise-level, custom quotes.
- Verdict: InEight is the preferred choice for large enterprise construction projects and owners focused on comprehensive project controls, where integrating schedule data with cost, risk, and performance management is paramount.
12. Jobber: Field Service Management for Small Contractors
Jobber is a field service management platform used by over 250,000 service businesses, including plumbers, electricians, landscapers, and small construction contractors. It centralizes client communication, quoting, invoicing, dispatch, and basic job scheduling.

As a construction scheduling tool, Jobber is not designed for advanced project schedule management. Its scheduling module focuses on calendar views and appointment management rather than Gantt charts, critical path analysis, baselines, or high-resource intensity planning. While it excels at simple assignment and team dispatch for service-oriented tasks, it is insufficient for multi-week construction schedules involving complex interdependencies. For small service contractors who primarily manage appointments and technician schedules, Jobber performs admirably.
- Key Strengths: User-friendly for field service businesses, excellent client communication and quoting features, efficient dispatch and appointment scheduling, integrated invoicing.
- Limitations: Lacks advanced




{kind=link}